Integración vocal (hardware)

¿Cómo integrar la interacción vocal?
Esta es una guía rápida para crear un primer prototipo de asistente de voz con el hardware y el software necesario.
Que coincidimos en que las tecnologías de voz han tenido un desarrollo acelerado y que hoy son parte clave en la experiencia de usuario lo daré por descontado si ya estás leyendo esta nota.
También asumiré un conocimiento general acerca de los componentes o servicios de un sistema de voz que, en breve, son:
- Captura y procesamiento de audio
- Reconocimiento automático del habla (ASR)
- Procesamiento y comprensión de lenguaje natural (NLU & NLP)
- Clasificación y gestión de intenciones
- Síntesis vocal / Presentación de información (TTS)
Cada uno de estos componentes puede funcionar de manera local o remota, configurando una experiencia completamente privada y desconectada de la internet, mixta o dejando en mano de servicios on-line desde el Automatic Speech Recognition hasta el Text to Speech.
La configuración del hardware
Para que las cosas funcionen de manera fluida os recomiendo una configuración sencilla y robusta.
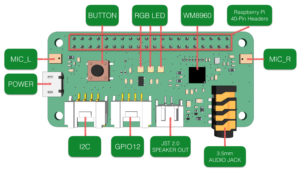
ReSpeaker 2-Mics Pi HAT con un coste en torno a los 12€ es una placa de expansión de doble micrófono que incluye 3 led RGB, un botón de usuario e interfaces para expandir la funcionalidad.
Los dos micrófonos dan la posibilidad de realizar procesamiento de señal para eliminar ecos y ruidos de fondo de manera más eficiente. Hay placas de expansión con más micrófonos y procesamiento digital de señales que hacen aún más eficiente la captura de audio, pero con esta configuración se desempeña de manera óptima en la mayor parte de los entornos.

Hemos utilizado una Raspberry Pi 3 Model Bque tiene un precio entorno a los 40€ aunque puede funcionar con una Raspberry Pi Zero.
También hará falta una tarjeta Micro SD de al menos 16Gb, una fuente de alimentación Micro USB de al menos 2.5A, y un altavoz o auriculares, accesorios muy comunes para smartphones.
El software que vamos a utilizar
Damos por descontado que en la MicroSD tenemos una versión, al menos, Raspberry Pi OS Buster.
Nos aseguraremos de que el sistema operativo está actualizado:

Obtenemos el código fuente de la placa de expansión de sonido, lo instalamos y reiniciamos:
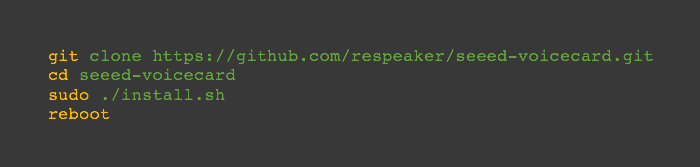
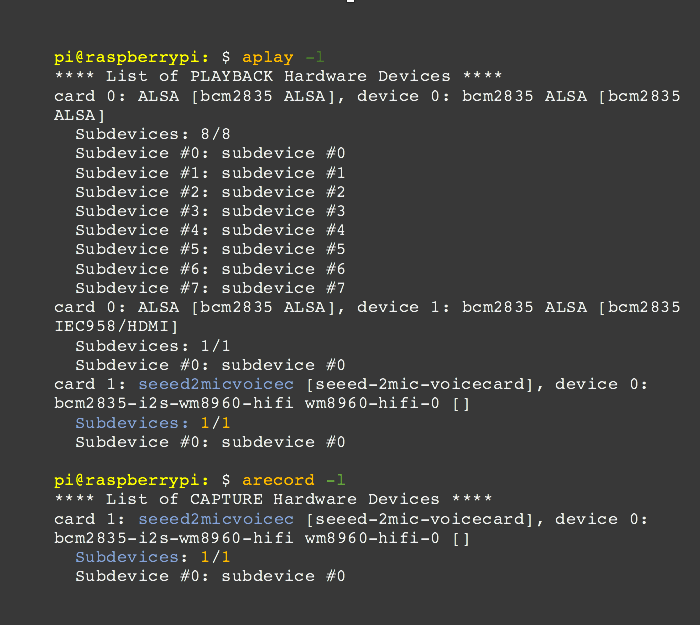
Comprobamos que la placa de sonido es reconocida como entrada y salida:
Editamos el archivo /boot/config.txt para desactivar el sonido integrado de la Raspberry.

La solución integrada de voz

Rhasspy es un proyecto de código abierto que combina múltiples servicios para dar una solución integral que nos permite configurar un asistente de voz funcional en muy poco tiempo.
La manera más simple y rápida de instalar Rhasspy es utilizando Docker que instalaremos con el siguiente comando:

Una vez instalado vamos a agregar el usuario pi al grupo docker y reiniciaremos.

Cuando las Raspberry haya reiniciado instalaremos la imagen Docker de Rhasspy

Al terminar la descarga ejecutaremos el siguiente comando:
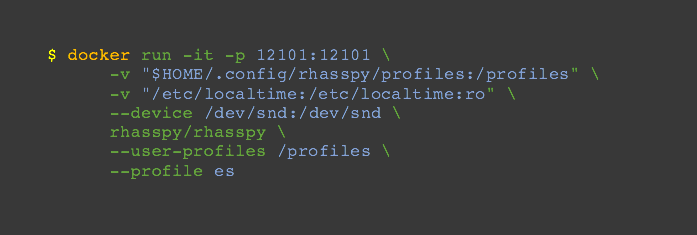
Se iniciará una imagen Docker a la que podremos acceder en el port 12101 de las Raspberry Pi, con el tiempo local, la interfaz de audio por defecto y un perfil en español.
¡Y con eso hemos terminado la configuración inicial!
Si apuntamos nuestro navegador a: http://<IP_ADDRESS>:12101, donde <IP_ADDRESS> es la dirección de nuestra Raspberry, accederemos a la interfaz web de Rhasspy.
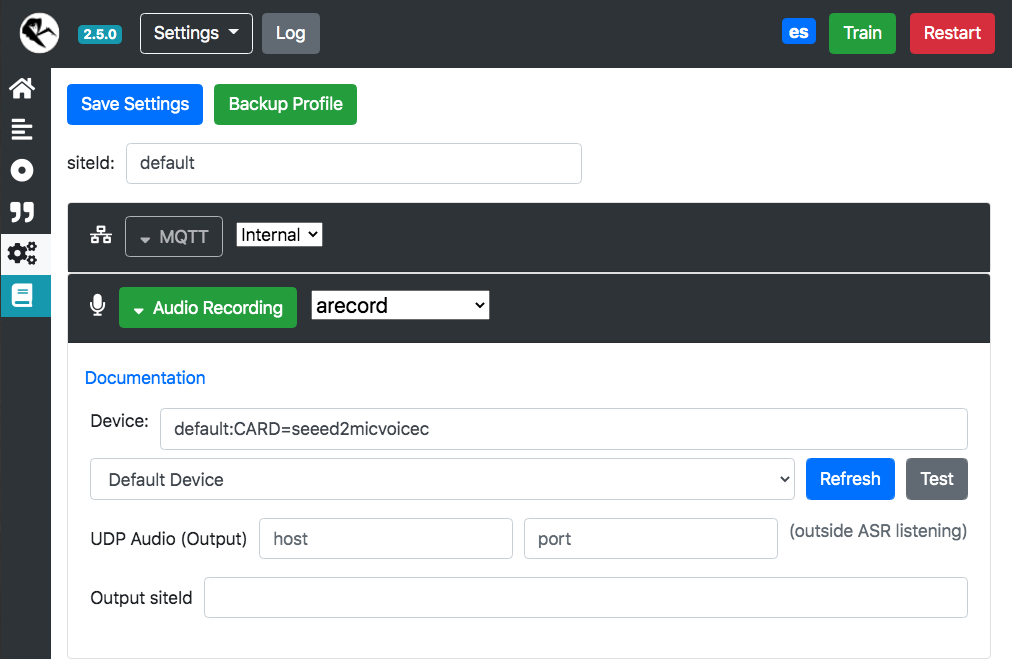
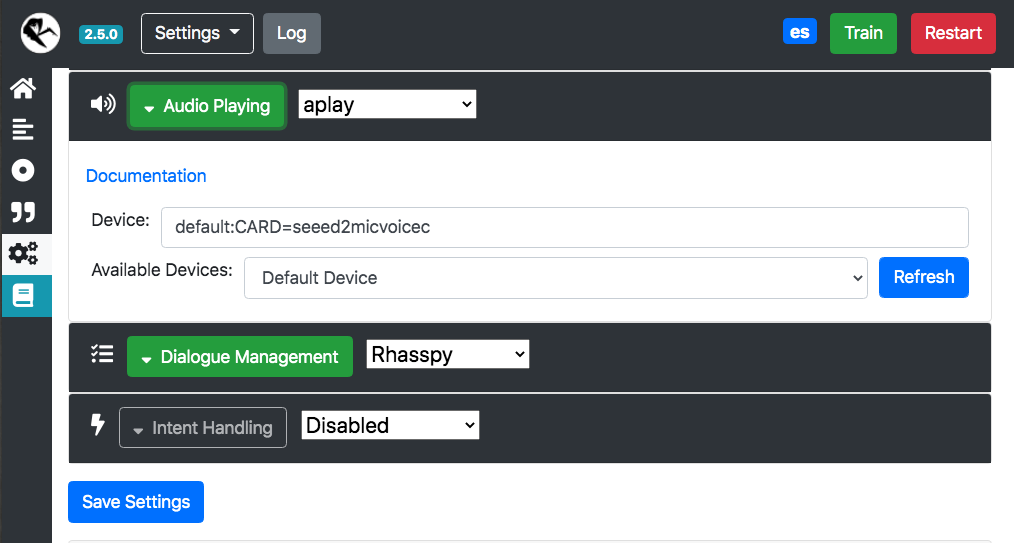
Vamos a realizar una configuración básica, primero vamos a configurar el dispositivo de audio, de los íconos a la izquierda elegimos “Settings”, luego seleccionamos “Audio Recording” y hacemos “Refresh” para elegir la tarjeta “seeed2micvoicec”
Buscamos la opción “Audio Playing” y repetimos la misma operación para buscar el dispositivo correcto, salvamos la configuración y aceptamos el mensaje “restart Rhasspy”
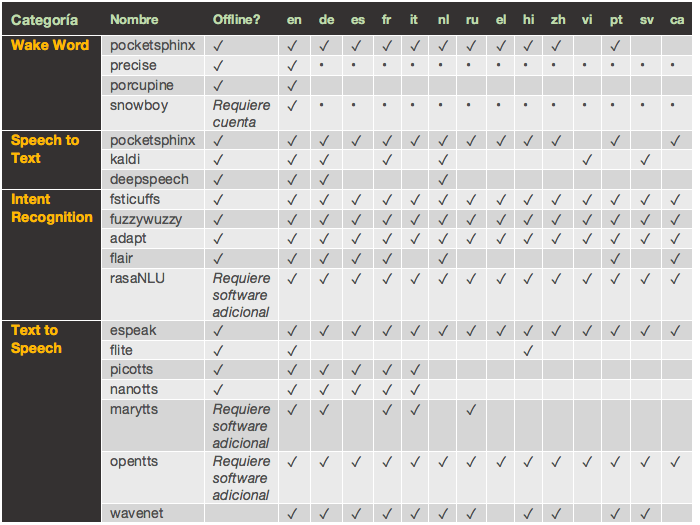
Vamos a configurar un “Wake Word” y algunos “Intents” para probar el funcionamiento. Rhasspy integra los siguientes paquetes que soportan los lenguajes enumerados en la tabla.
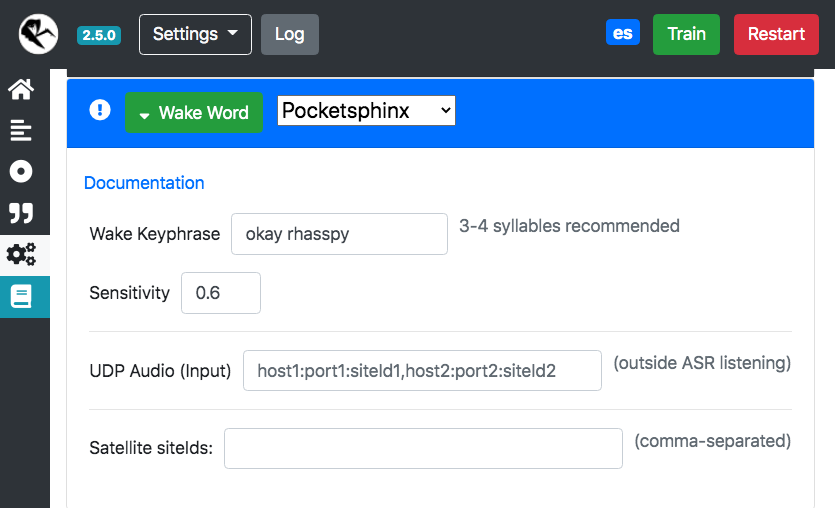
Wake Word
Para la palabra de activación utilizaremos Pocketsphinx que aunque su performance es de las más bajas sirve para el propósito de una configuración rápida. Vamos a utilizar “okay rhasspy” y dejaremos las sensibilidad en 0.6
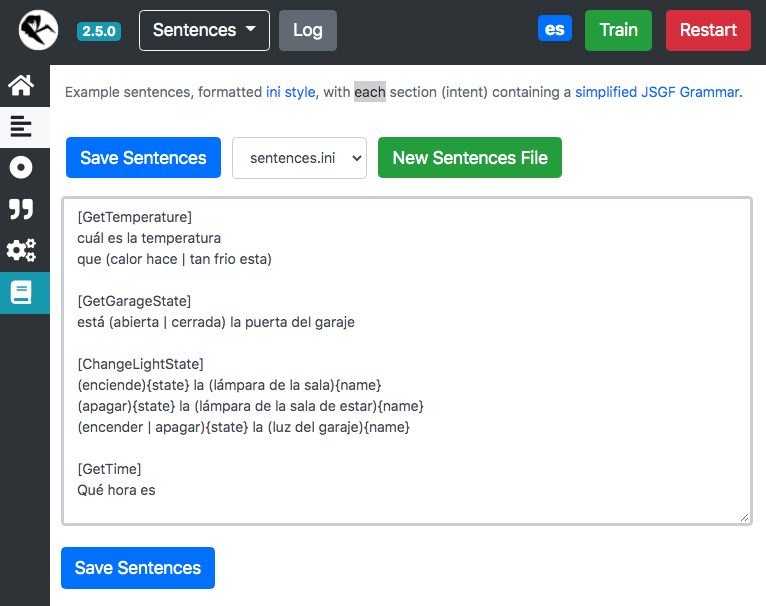
Intents
Vamos a crear unas oraciones para entrenar el modelo que discernirá las intenciones del diálogo con los usuarios.
¡Ahora es el momento de la prueba definitiva!
“Okay Rhasspy, ¿Qué hora es?”
Escucharemos el beep del wakeword, el beep de final de captura y obtendremos esta información en log:
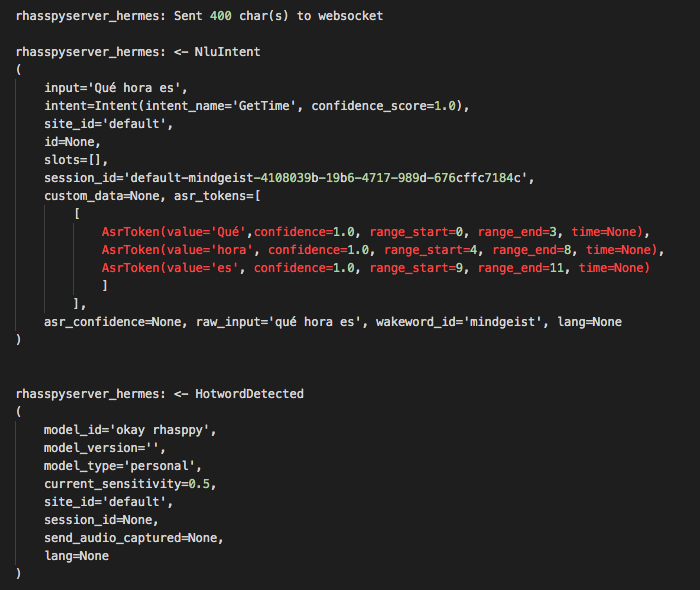
Rhasppy implementa Hermes, un sistema de mensajería de la plataforma Snips que a su vez utiliza el protocolo Mosquito (MQTT), un protocolo ideado para la comunicación entre dispositivos (M2M) en la Internet de las cosas (IOT), para notificar de un evento que haya detectado a partir de la intención de un usuario que interactúa con la plataforma.
En el Log vemos dos mensajes, HotwordDetected y NluIntent con los datos de la interacción, ahora estamos preparados para desarrollar una aplicación que responda a estos eventos de voz.
Este es el punto de partida para integrar la interacción de voz en un proyecto de hardware, desde la automatización y la interacción transaccional hasta la narrativa interactiva.
Puede ser la piedra angular de un juego de mesa operado por voz, el motor de comprensión de instrucciones verbales para navegar un catálogo o lo que seas capaz de imaginar.
Sin necesidad de conexión a internet y sin conflictos de privacidad.
En Mindgeist podemos ayudarte a pensar cómo integrar la voz en tu producto, en tu experiencia de usuario, en tu estrategia de marketing, en cómo contar una historia o en todo eso junto.